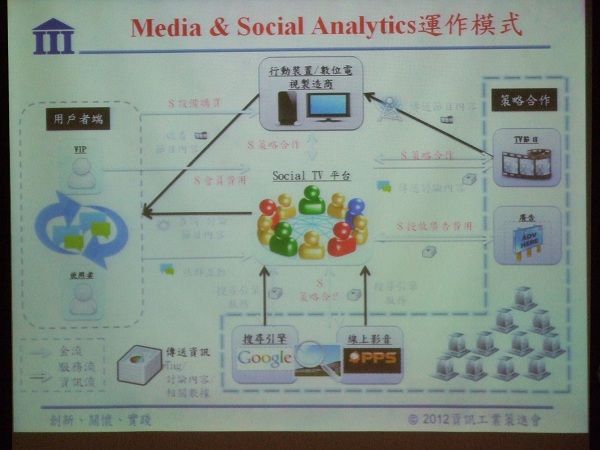
Java and Big Data 大資料時代的處理方式

什麼是 Big Data?
Big Data 通常指大量的資料群集,其數量大於一般軟體工具在有限的時間內所能處理的範圍。
在 IT 的領域裡,Big Data的資料量已經大到難以用一般資料庫管理工具處理,包括 capture, curation, storage, search, sharing, analysis and visualization 等範疇。其發展的趨勢源自於對大量數據分析時所衍生的相關額外資訊。
有別於少量的數據分析,Big Data 的分析對各領域的相關性研究有正面的助益,例如商業趨勢、疾病預防、合法引用(著作權議題)、防制犯罪以及火車即時管理系統等。
截至 2008 年,儘管數據單位的使用限制已經由 PB 等級(PetaBytes)增長到 EB 等級(ExaBytes),仍然
有許多科學家遇到大量數據使用的限制。
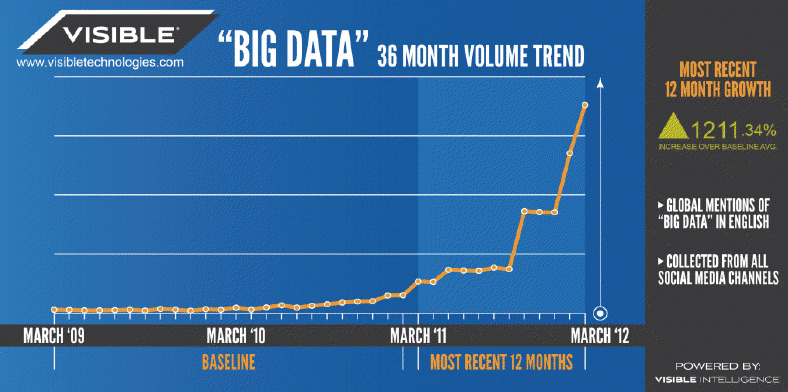
最近 12 個月被提到的次數,成長了 12 倍(資料來源)
Big Data 難以用關聯式資料庫,桌面應用程式以及虛擬化工具來操作,其替代方案需要數以百計甚至數以千計的伺服器同時多工處理做運算,才可以處理如此海量的數據。何謂 Big Data 有時因組織而異。對有些組織來說,數百
GigaBytes 的資料量增加可能就需要導入新的資料管理模式。然而對某些組織來說,資料量要大到數百 TeraBytes 之譜,才需要考慮相關問題。
Java and Big data
Java 技術跨平台的特性,已經逐漸變成軟體程式開發主流,從銀行大型主機到網頁上的 applet,各領域對 Java 技術的應用都呈現爆炸性的成長。過去 Java 高移植性的特性帶來執行期效能低落的負面評價,隨著 Java HotSpot Virtual Machine的出現,逐漸獲得改善。
Java HotSpot VM 新增的一些特點,對執行大型資料的效能上可以獲得提升,我們由平台架構幾點特色來做探討:
Memory Model
以往 JVM 對物件的存取採用 indirect handles 的方式,以方便在回收垃圾期間能更快的重新定址。然而此法代表存取 instance variables 需要兩層的 indirection,因而產生效能瓶頸。新一代Java HotSpot VM 對於物件之間的參考,直接實作成指標,存取物件時可以有類似 C 語言的速度,當物件在記憶體被重新定址時,garbage collector將負責尋找和更新物件中所有的參考。物件的 header 也由傳統 Virtual Machine 的 three machine-word header 變成 two machine-word header,節省近 8% 的heap size。第一個 header word保存了識別碼和 GC 的資訊,第二個 header word 保存了物件的類的參考。只有陣列有第三個 header machine-word,用來儲存陣列的大小。
Garbage Collection
Java HotSpot VM 記憶體系統提供具有彈性的垃圾回收管理,針對特定的程式需求使用不同的演算法。一般的 garbage collector 使用較為不精確的回收方式,在擴充不支援 garbage collection 的系統時較為便利,但是會有易於記憶體洩漏,不允許物件轉移和可能造成記憶體 (heap) 破碎等缺點。
Ultra-Fast Thread Synchronization
Thread 的實作也有重大的突破,藉由 ultra-fast 和 constant-time 的技術加速執行緒處理速度,並且能夠在擁有大量共享記憶體的多處理器伺服器上能夠立刻做到高效的同步處理能力。
64-bit Architecture
早期的 Java HotSpot VM 限制於使用 4 Gigabytes 的記憶體,甚至在64-bit作業系統也是如此,例如Solaris OE。隨著伺服器的記憶體不斷的擴充,現行的 64-bit JVM 已經可以完全的使用記憶體,避免資源的浪費。對程式來說記憶體的完全利用可以減少對硬碟和資料庫的存取次數,大大的改善了程式運行的效能。
在64-bit JVM的環境下,Object Packing 功能減少了不同資料型態容量造成記憶體浪費的問題,以下程式片段為例:
Public class Button {
Char shape;
String label;
int xposition;
int yposition;
char color;
int joe;
object mike;
char armed;
}
這段程式就會造成使用空間的浪費 (color 和 joe 需要 3 bytes 填滿,joe 和 mike 在 64-bit 環境下須要 4 bytes 填滿),經優化後變數會被記錄如下:
Object mike;
int joe;
char color;
char armed;
這樣將不會有空間被浪費。

Java HotSpot Virtual Machine 已經成為新一代Java平台技術核心
以上大致介紹了 Big Data 在各領域使用的趨勢以及 Java 新一代平台處理資料的能力。當然系統處理大量資料時需要注意的環節很多,伺服器端有 loading balancing 和 auto scaling 等議題,資料庫端有 NoSql 取代RDBMS 的議題。今天就針對用新一代 Java 環境編寫大量資料所面對的挑戰做討論,將來有機會再和大家分享其他層面的技術。